





















Meta-CoT operates like a structured reasoning engine — it decomposes editing tasks into fundamental meta-operations, reasons step-by-step through a triplet framework, and aligns CoT with editing output through reinforcement learning.
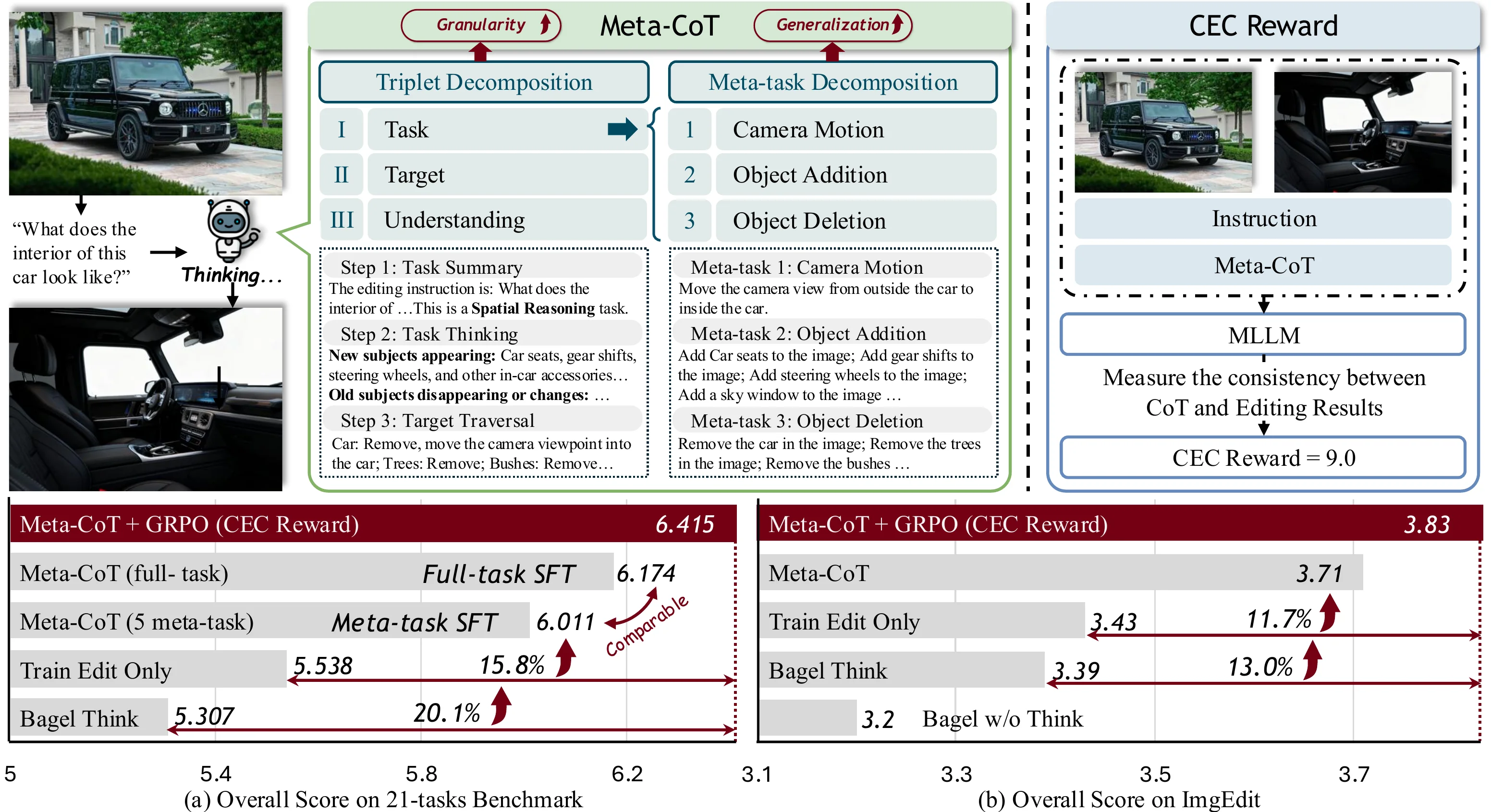
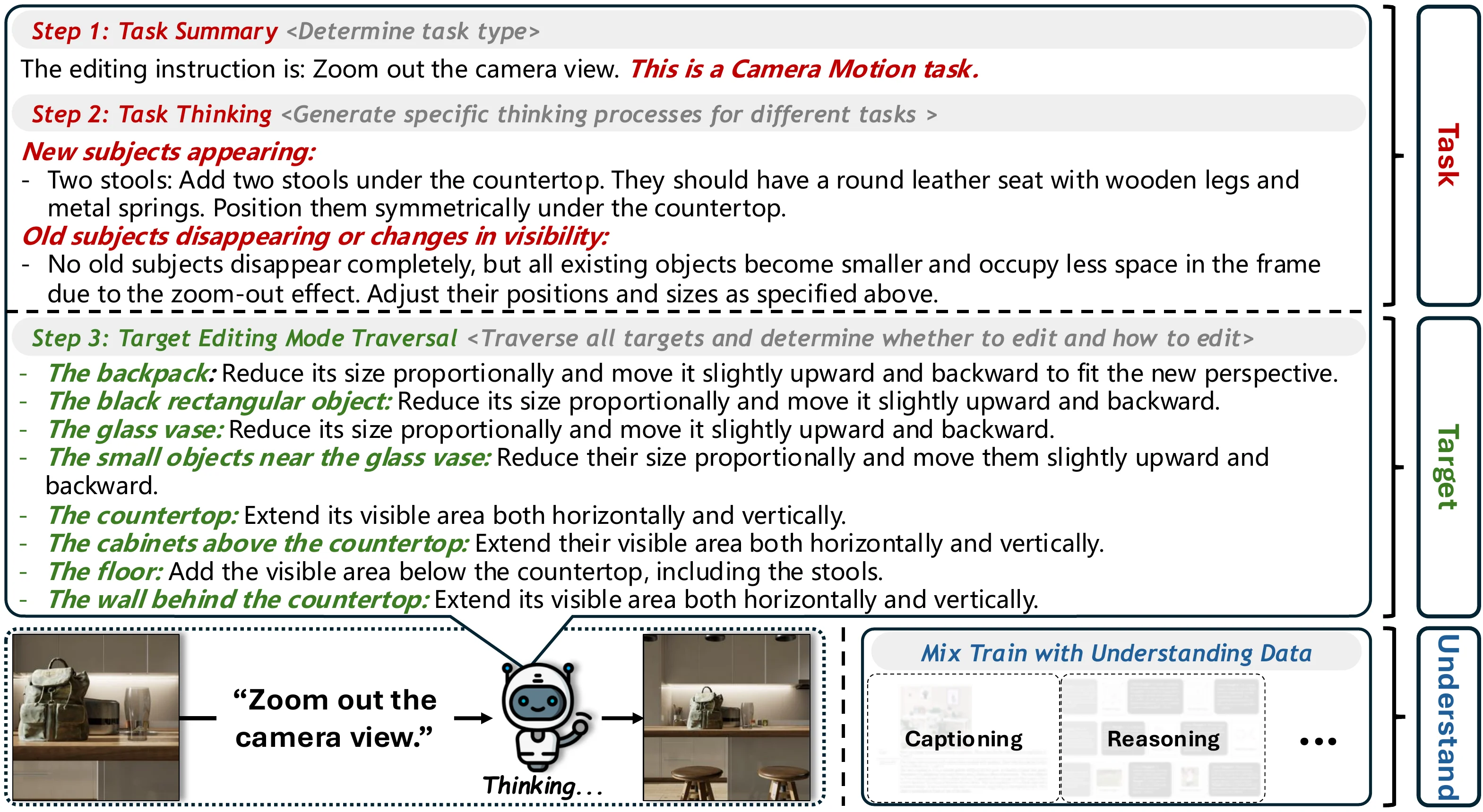
Figure 1. Overview of Meta-CoT. We propose a two-level decomposition paradigm: (1) Triplet Decomposition into task, target, and understanding; (2) Meta-task Decomposition into five fundamental meta-tasks for generalization.
Abstract
Unified multi-modal understanding/generative models have shown improved image editing performance by incorporating fine-grained understanding into their Chain-of-Thought (CoT) process. However, a critical question remains underexplored: what forms of CoT and training strategy can jointly enhance both the understanding granularity and generalization? To address this, we propose Meta-CoT, a paradigm that performs a two-level decomposition of any single-image editing operation with two key properties: (1) Decomposability. We observe that any editing intention can be represented as a triplet — (task, target, required understanding ability). Inspired by this, Meta-CoT decomposes both the editing task and the target, generating task-specific CoT and traversing editing operations on all targets. This decomposition enhances the model's understanding granularity of editing operations and guides it to learn each element of the triplet during training, substantially improving the editing capability. (2) Generalizability. In the second decomposition level, we further break down editing tasks into five fundamental meta-tasks. We find that training on these five meta-tasks, together with the other two elements of the triplet, is sufficient to achieve strong generalization across diverse, unseen editing tasks. To further align the model's editing behavior with its CoT reasoning, we introduce the CoT-Editing Consistency Reward, which encourages more accurate and effective utilization of CoT information during editing. Experiments demonstrate that our method achieves an overall 15.8% improvement across 21 editing tasks, and generalizes effectively to unseen editing tasks when trained on only a small set of meta-tasks.
Key Features
Three core innovations that enable granular understanding and broad generalization in image editing.
Triplet Decomposition
Decomposes any editing intention into a structured triplet: (task, target, required understanding) — enabling fine-grained reasoning over every editing element.
Meta-task Generalization
Five fundamental meta-tasks (add, delete, replace, camera motion, position change) are sufficient to generalize across 21+ diverse editing tasks.
CEC Reward
CoT-Editing Consistency Reward uses a VLM to align the model's reasoning chain with its actual editing output via reinforcement learning.
Method
Triplet Decomposition
We observe that any editing intention can be decomposed into a triplet: (task, target, required understanding ability). This insight drives our first-level decomposition.
- Task: Identifies the editing operation type (e.g., replacement, addition, camera motion)
- Target: Traverses all objects and regions that need to be edited
- Understanding: Determines the visual understanding capability required
Meta-task Decomposition
In the second decomposition level, we break down all editing tasks into five fundamental meta-tasks:
- Addition — Adding new objects or elements
- Deletion — Removing existing objects
- Replacement — Swapping objects or attributes
- Camera Motion — Changing viewpoint or perspective
- Position Change — Moving objects spatially
Training on just these five meta-tasks achieves performance comparable to full-data training on 21 diverse editing tasks.

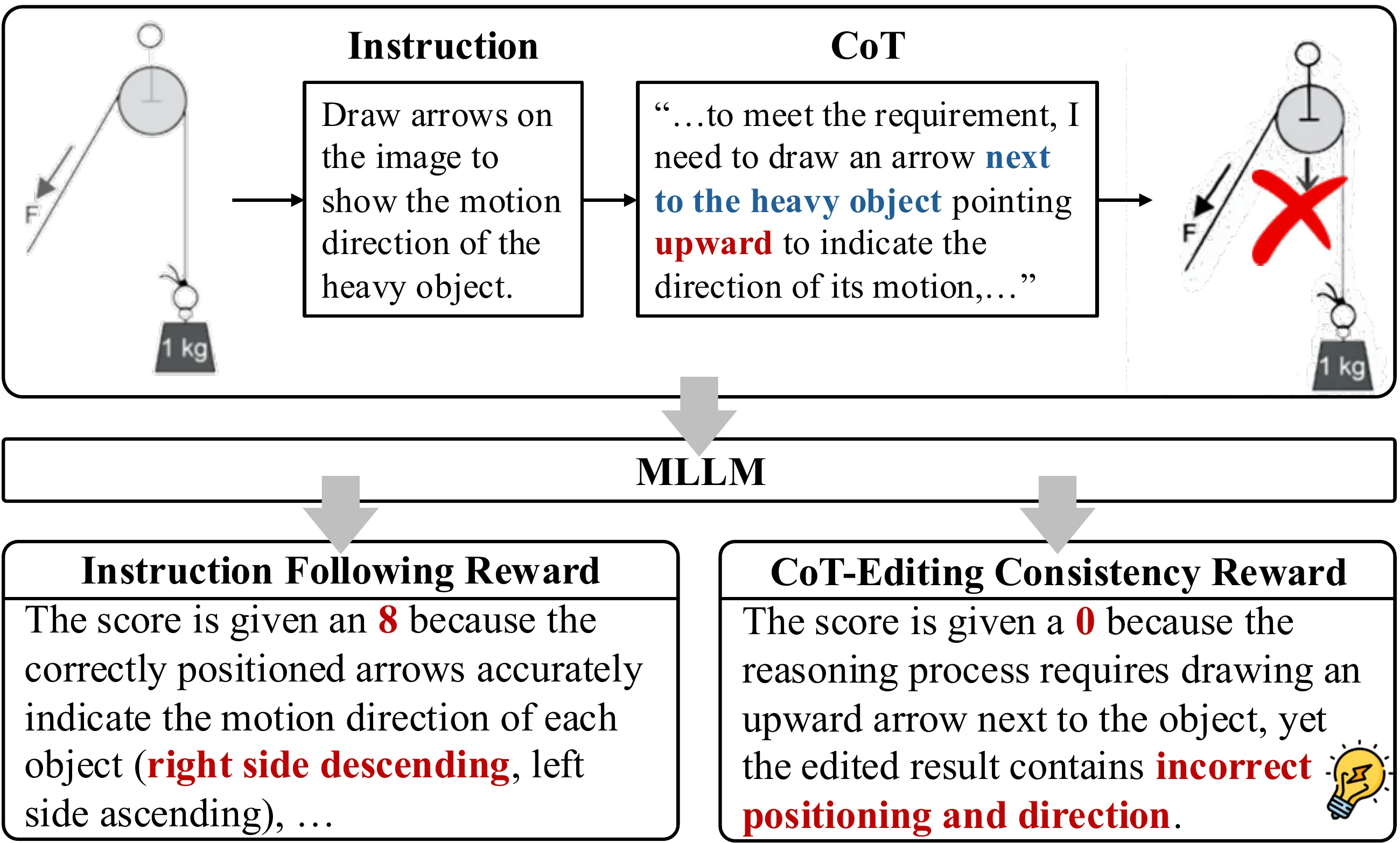
CoT-Editing Consistency Reward
A key challenge is ensuring the model's editing behavior is actually aligned with its CoT reasoning. We propose the CEC Reward:
- Leverages a VLM (Qwen2.5-VL) to measure consistency between CoT and editing output
- Rewards edits that faithfully follow the reasoning chain
- Integrated into a Flow-GRPO reinforcement learning framework
Training Pipeline
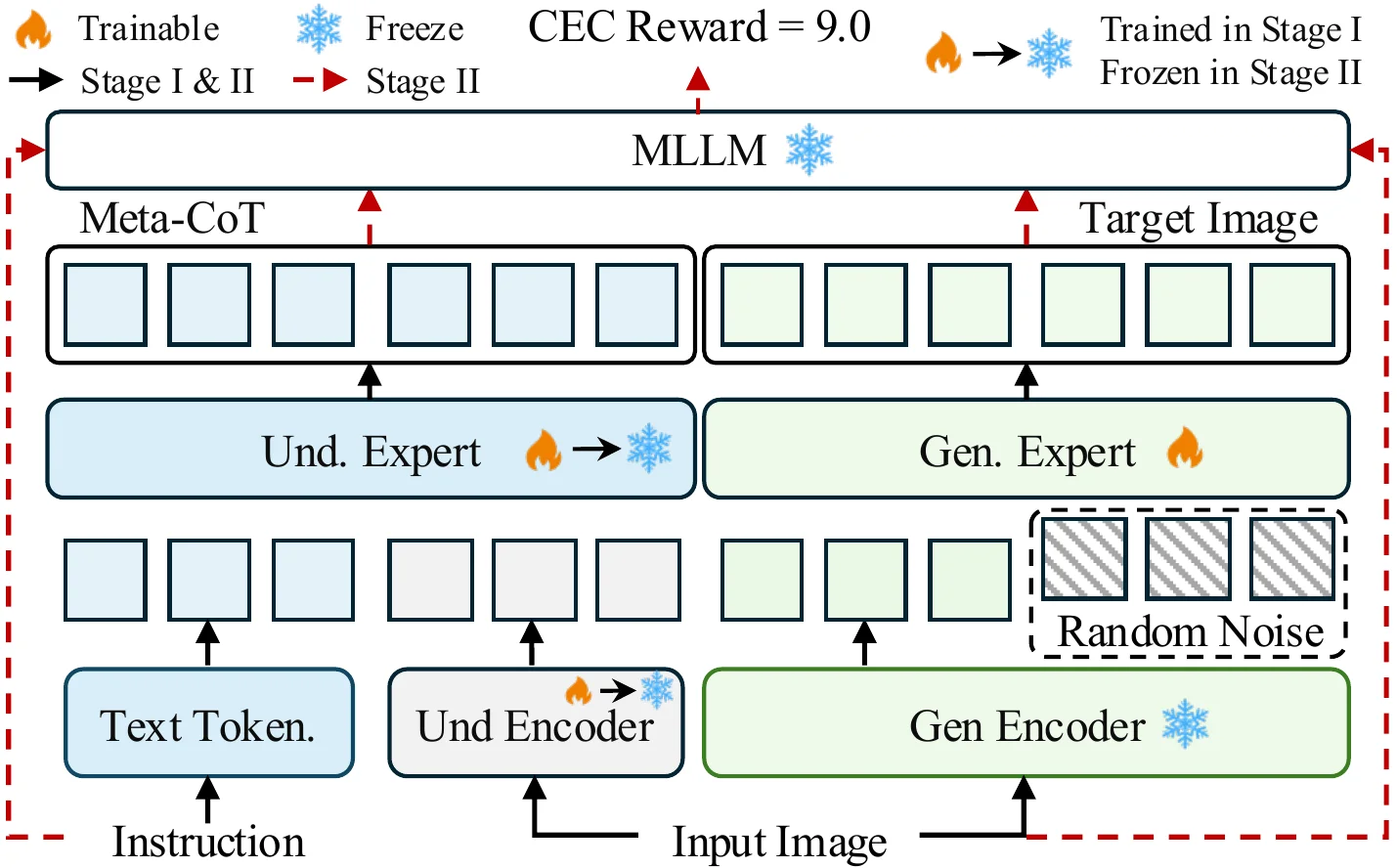
Stage 1: SFT on reasoning and editing. Stage 2: Flow-GRPO with CEC reward.
Data Construction Pipeline
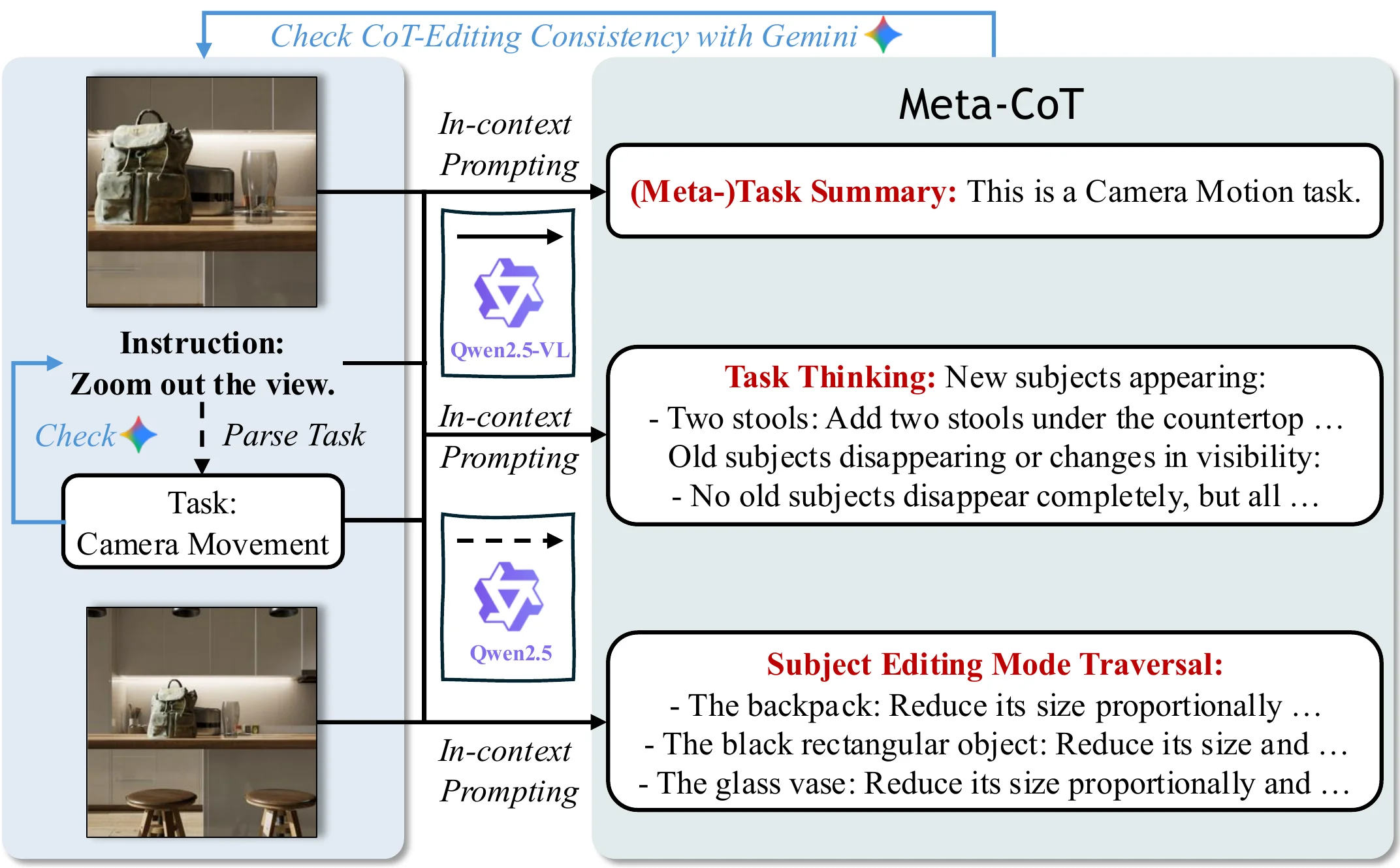
Automated pipeline for Meta-CoT training data with triplet annotation.
Qualitative Results
Qualitative Comparison with CoT

Quantitative Results
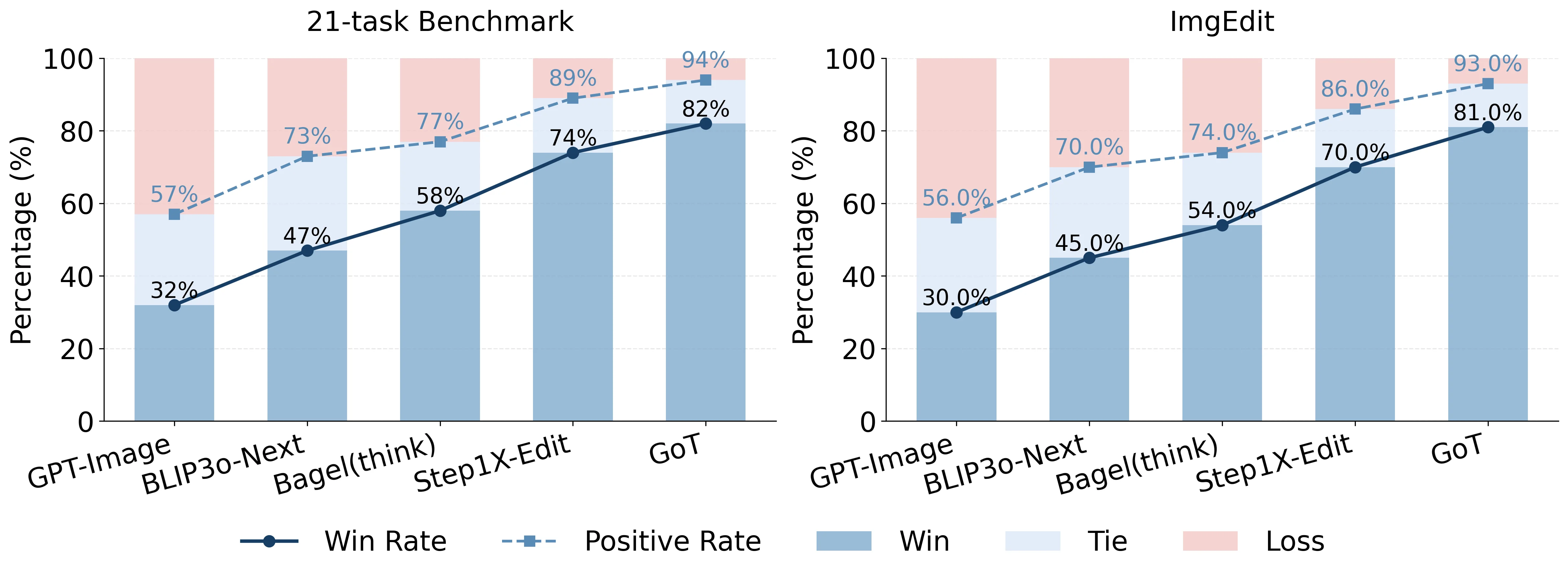
Table 2. Overall Scores on the 21-Task Benchmark (GPT-4.1 evaluated)
| Method | Background | Color | Material | Action | Human Attr. | Style | Add | Remove | Replace | Text | Tone | Average |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Baselines | ||||||||||||
| Bagel (w/o think) | 6.172 | 6.668 | 6.024 | 4.182 | 4.933 | 6.460 | 5.102 | 5.814 | 5.226 | 5.612 | 6.213 | 5.673 |
| Bagel (w/ think) | 6.686 | 6.469 | 5.969 | 3.997 | 4.404 | 5.783 | 4.764 | 5.221 | 4.963 | 5.530 | 4.591 | 5.307 |
| Train Editing Only | 6.743 | 6.537 | 6.052 | 4.155 | 4.710 | 6.060 | 4.960 | 5.600 | 5.170 | 5.620 | 5.310 | 5.538 |
| Ours | ||||||||||||
| SFT (Meta-CoT) | 7.173 | 7.201 | 6.493 | 4.470 | 5.384 | 6.920 | 5.730 | 6.340 | 6.110 | 5.560 | 7.080 | 6.224 |
| Meta-CoT + RL (Ours) | 7.342 | 7.365 | 6.711 | 4.812 | 5.653 | 7.105 | 5.924 | 6.528 | 6.287 | 5.442 | 7.396 | 6.415 |
Table 3. System Comparison on ImgEdit (GPT-4.1 evaluated)
| Method | Add | Adjust | Extract | Replace | Remove | Background | Style | Hybrid | Action | Overall |
|---|---|---|---|---|---|---|---|---|---|---|
| Closed-source Models | ||||||||||
| FLUX Kontext [Pro] | 4.25 | 4.15 | 2.35 | 4.57 | 4.00 | 1.81 | 3.19 | 2.68 | 2.76 | 4.26 |
| GPT Image 1 [High] | 4.61 | 4.33 | 2.90 | 4.93 | 4.20 | 2.77 | 3.55 | 3.76 | 3.82 | 4.57 |
| Open-source Models | ||||||||||
| Step1X-Edit | 3.08 | 3.21 | 2.24 | 3.84 | 3.05 | 2.04 | 2.85 | 1.91 | 2.65 | 3.14 |
| SeedEdit | 3.16 | 3.19 | 2.64 | 4.19 | 2.96 | 2.52 | 2.85 | 1.56 | 2.98 | 3.32 |
| BAGEL (w/o think) | 3.08 | 3.21 | 1.75 | 3.76 | 2.70 | 1.44 | 2.38 | 1.20 | 1.46 | 3.20 |
| BAGEL (w/ think) | 3.16 | 2.83 | 2.24 | 3.84 | 2.96 | 2.04 | 2.85 | 1.56 | 1.91 | 3.39 |
| Ours | ||||||||||
| Meta-CoT + RL (Ours) | 4.38 | 4.81 | 3.82 | 4.69 | 4.27 | 3.06 | 4.63 | 2.64 | 3.68 | 3.83 |
Human Evaluation
Pairwise human preference study comparing Meta-CoT against baseline methods.